Уфа
Что делать, если не получается просканировать сайт?

Автор статьи
Андрей Буйлов
В статье поговорим о нечастой на самом деле ситуации, когда не получается просканировать ваш сайт так, как вам нужн.
И подписчик спрашивает: «Сайт на OpenCart, к примеру, если начинать сканировать лягушкой с карточки товара, краулер будет сканировать абсолютно весь сайт, переходя по ссылкам. Если так же поступить с другим большим магазином, лягушка просканирует часть ссылок. Вопрос: нужно поставлять заглушки, чтобы не расходовать краулинговый бюджет? Как это реализовать, как правильно дать задание программисту?»
Будет ли расходоваться краулинговый бюджет
Во-первых, я не совсем понимаю о каких заглушках речь, честно говоря, но, в общем, ничего делать не нужно, не надо никакие заглушки ставить.
Во-вторых, про неоптимальный расход краулингового бюджета имеет смысл говорить, когда у вас какие-то мусорные страницы в индекс попадают. То есть при ситуации, когда просто Screaming Frog не сканирует какие-то разделы, в общем, это не признак того, что краулинговый бюджет тратится куда-то не туда.
Работа со Screaming Frog
Если я правильно понимаю то, о чем вы говорите, то в Screaming Frog есть опция Spider Configuration, и здесь можно выбрать, как сканировать.
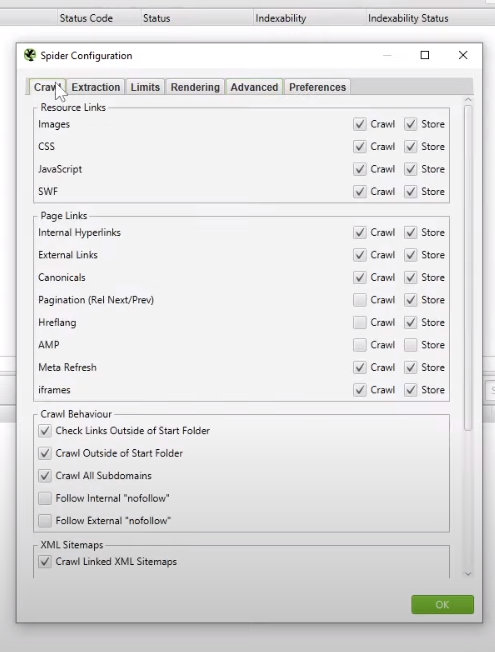
То есть можно поставить две 2 галки во вкладках Crawl есть Check Links Outside of Start Folder и Crawl Outside of Start Folder. Если вы начали с главной страницы, то эти галки значения не имеют, а вот если с внутренней страницы, то программа смотрит маску УРЛа. Вот программа выдает пример.
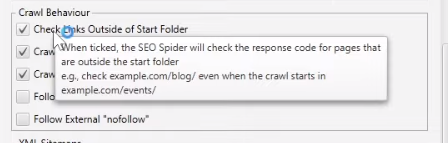
Вот например, у вас есть example.com/blog. Если вы обе галки сняли (с Crawl есть Check Links Outside of Start Folder и Crawl Outside of Start Folder), то Screaming Frog не будет ходить и смотреть ссылки вне этой папки. То есть если не поставить в первой вкладке, то со всех страниц с адресом, не подходящим под эту маску example.com/blog (не начинающимся с этого) программа не будет даже ссылки собирать. А вот если не поставить во второй (Crawl Outside of Start Folder), он не будет ходить по ним, анализировать эти страницы.
Таким образом, скорее всего у вас эти галки сняты. И когда вы вводите рубрику одного сайта, то Screaming Frog ходит только по этой папке. А, например, если вводите рубрику другого сайта, то предполагаю, что там не папочная структура, и вы ввели адрес страницы, которая через параметры или еще как-то и не является папкой. И поэтому Screaming Frog у вас сканирует весь сайт. Либо вы сканировали в разное время, когда у вас эти галки стояли по-разному. Скорее всего так, если я правильно понял вопрос.
Поэтому здесь вопрос настроек Screaming Frog или аналогичного софта, и в связи с этим ничего менять особо не нужно.
То есть сделайте так, как вы хотите настроить:
Заглушки и прочее здесь не нужны.
Краулинговый бюджет вы будет экономить, когда просканируете весь сайт целиком и увидите, что у вас есть какие-либо мусорные страницы. Либо зайдите в панель Вебмастера Яндекса или через Google Search Console и увидите, что огромное количество страниц у вас добавилось в индекс просто потому, что была атака от конкурентов через распространение несуществующих страниц либо просто уязвимость нашли на вашем сайте и накидали туда таких спамных страниц, чтобы оттуда ссылки получить.
В общем, всякое бывает. И вот тогда да, чтобы краулинговый бюджет туда не тратился и чтобы это не вредило продвижению, нужно их закрывать. Все остальное из того, что вы описываете, если я правильно понял вопрос, то это в общем не проблема.