Уфа
Как быстро удалить частичные дубли запросов из семантического ядра

Автор статьи
Андрей Буйлов
В статье рассмотрим вопрос о том, как быстро удалить частичные дубли запросов из вашего семантического ядра, из списка запросов. Подписчик спрашивает: «Как автоматически скомбинировать запросы и удалить смысловые дубли/склонения? Если на старницу ведет 300 запросов».
Существует несколько способов, и разные люди решают этот вопрос разными методами: кто-то просто глазами пробегается, кто-то использует разный софт. И А.Буйлов лично, и в веб-студии «Муравейник» для это используют Key Collector, и также учит и на своем курсе.
Как убрать дубли с помощью сервиса Key Collector
Поиск схожих запросов
Допустим, у вас уже есть сгруппированные запросы, которые совместимы друг с другом на одной странице, и вам нужно дубли убрать. Либо просто в вашей семантике убрать все дубли.
В статье для примера возьмем конкретную страницу определенного сайта, там есть статья про отбеливание зубов. Выгружаем все запросы, по которым она продвигается. В данном случае эти запросы хоть как-то друг с другом совместимы, потому что одна и та же статья выходит по всем этим запросам. Пересечение по одной ссылке, конечно, слабое, но тем не менее.
Дальше открываем Кей Коллектор, создаем новый проект, добавляем запросы. Вы, разумеется, добавляете свой список.
Теперь нужно их проверить на наличие частичных дублей. Для этого есть специальный инструмент, который так и называется «Неявные дубли».
Нажимаете на кнопку, и в появившимся окне нужно выбрать:
В нашем случае фильтра нет, поэтому этот пункт не важен, список исключений также не нужен, как и синонимы.
Выбрав настройки, жмете «Найти». Он найдет и покажет группы и запросы.
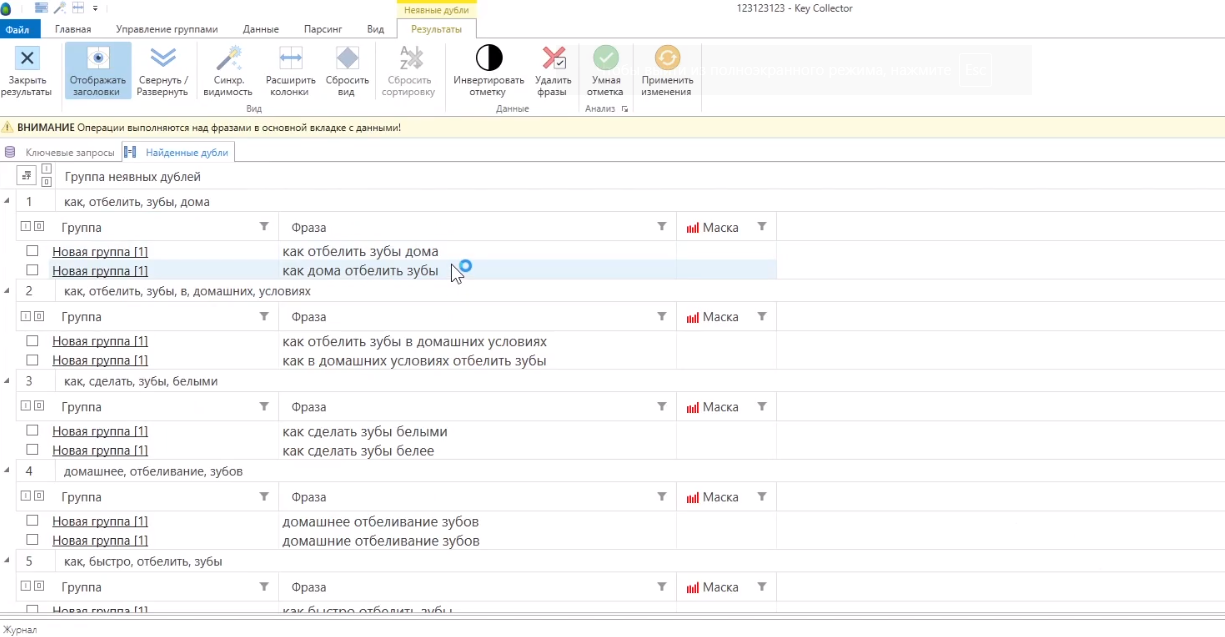
Видно, что сервис нашел «отзеркаленные» фразы, например, «как отбелить зубы в домашних условиях» и «как в домашних условиях отбелить зубы». Также очень похожие запросы, в которых незначительные изменения в одном слове — «домашнее отбеливание зубов» и «домашние отбеливание зубов»
В плане синонимов все несколько сложнее. Если не задавать список, то сервис, как правило, будет просто находить различные словоформы этих слов и зеркальные, например в данном случае — «отбеливание зубов перекисью водорода» и «перекись водорода отбеливание зубов». То есть словоформа меняется, но запрос, в принципе, тот же самый. И если вы не задали свои синонимы, то он так и будет делать.
Как выбрать нужный вариант запроса
Дальше вам просто нужно выбрать, какой из вариантов взять. Вопрос на самом деле сложный, особенно когда более-менее соизмеримые запросы. И для того, чтобы решить, вам нужно узнать их точную частоту. Тут вам не поможет парсинг через Яндекс.Директ, как обычно собираем.
Для примера, запускаем «Сбор статистики из Yandex Direct». Сервис собрал частоту запросов. И — обратите внимание — это частота без учета порядка слов. То есть собран вариант «в кавычках и с восклицательными знаками», то есть с точной словоформой, но без учета порядка слов. Для того, чтобы узнать и частоту фраз с определенным порядком слов, нужно выставить еще и квадратные скобки вокруг запросов, и это при подобном сборе статистике через Директ сделать нельзя. Для этого нужен сбор частоты из Yandex Wordstat.
Однако, так как запросов может быть много, а участвующих в выборе, какие именно взять, — не так много, то можно точную частоту собирать не для всех фраз, а только для тех, которые нужны. Для этого нужно перейти на вкладку с дублями, выбрать запросы, которые там есть (в нашем случае сервис показывает, что их 48 из 316) и нажать кнопку «Применить изменения».
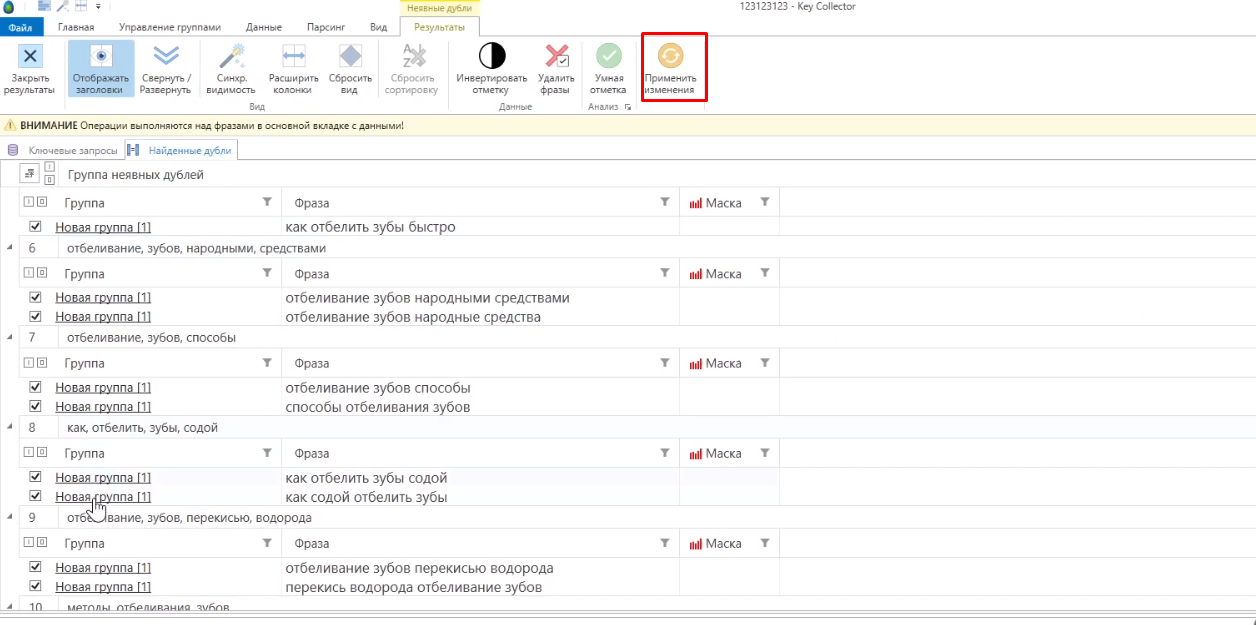
Это нужно для того, чтобы все эти запросы автоматически были отмечены во вкладке с ключевыми словами.
Таким образом, для 48 фраз нужно собрать частоту по Вордстат. Но перед этим выбрать, чтобы использовались только те запросы, которые отмечены. Для этого переходите во вкладку «Общее» (Файл — Настройки — Общее).
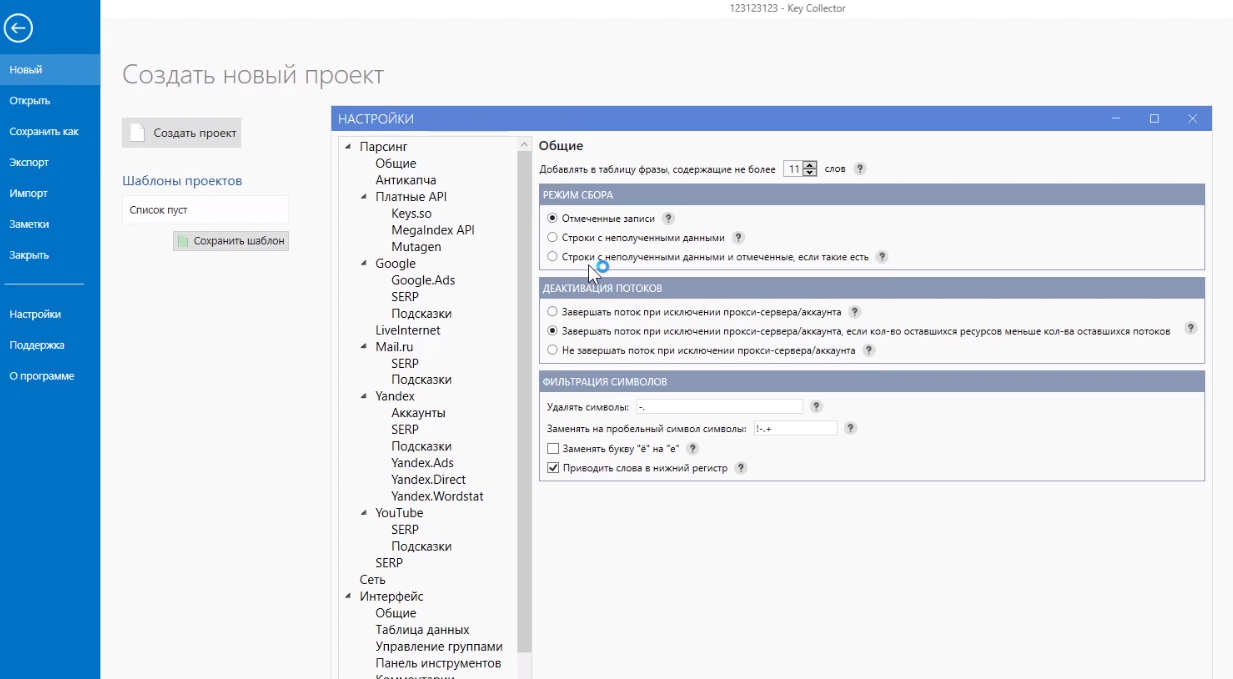
И здесь в блоке «Режим сбора» выбираете «Отмеченные записи», а не «Строки с неполученными данными». Тогда он будет собирать частоту только тем запросам, которые были отмечены галочкой.
Дальше переходите вновь во вкладку с ключевыми словами, нажимаете кнопку «Сбор частот Yandex Wordstat». В появившимся окне выбираете базу данных (в данном случае — все), нужный вам регион и в пункте «режим» выбираете только последний вариант (с кавычками, квадратными скобками, восклицательным знаком). Жмете «Начать».
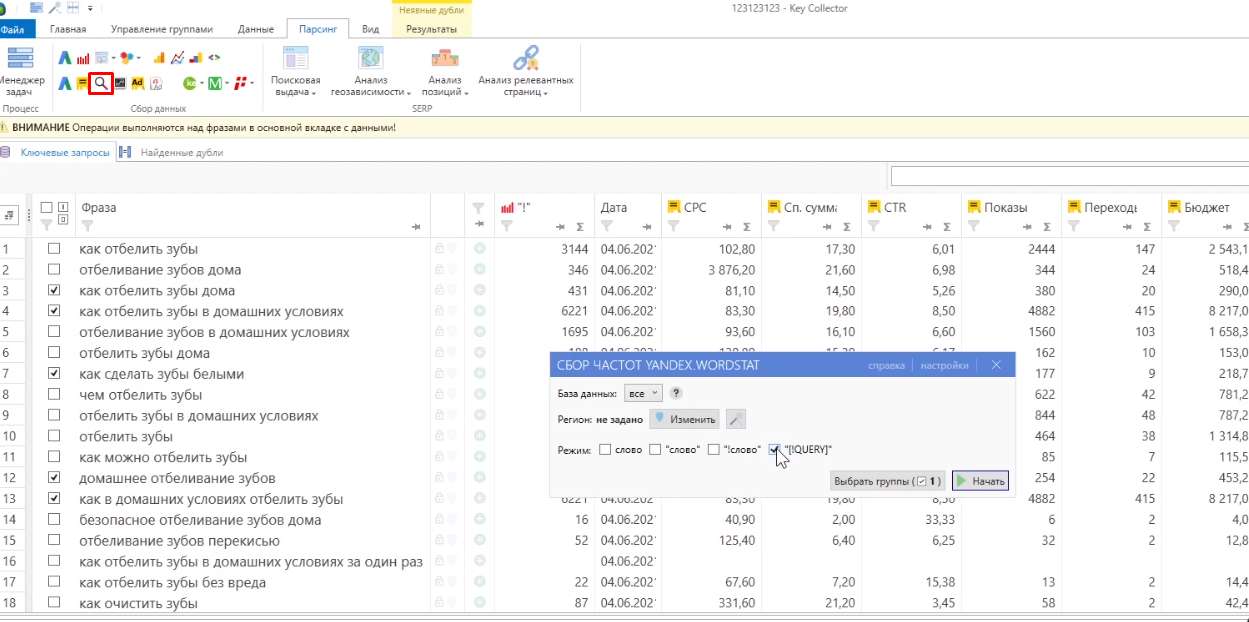
Здесь нужно будет подождать дольше, потому что если в Яндекс.Директ он закидывает сразу несколько десятков запросов и по этим десяткам собирает данные, то в случае с парсингом через Вордстат он кидает по одному запросу. Соответственно, если у вас нет прокси-серверов и у вас не так много аккаунтов Яндекса, подключенных к Key Collector, то он будет это делать очень долго. Но тем не менее для этой задачи такая операция нужна.
Так как это долго, то собираете частоту не для всех запросов с учетом порядка, а только для тех, по которым есть сомнения, какой из них выбрать.
Когда запросы собраны, видно, у какого из дублей частота выше.
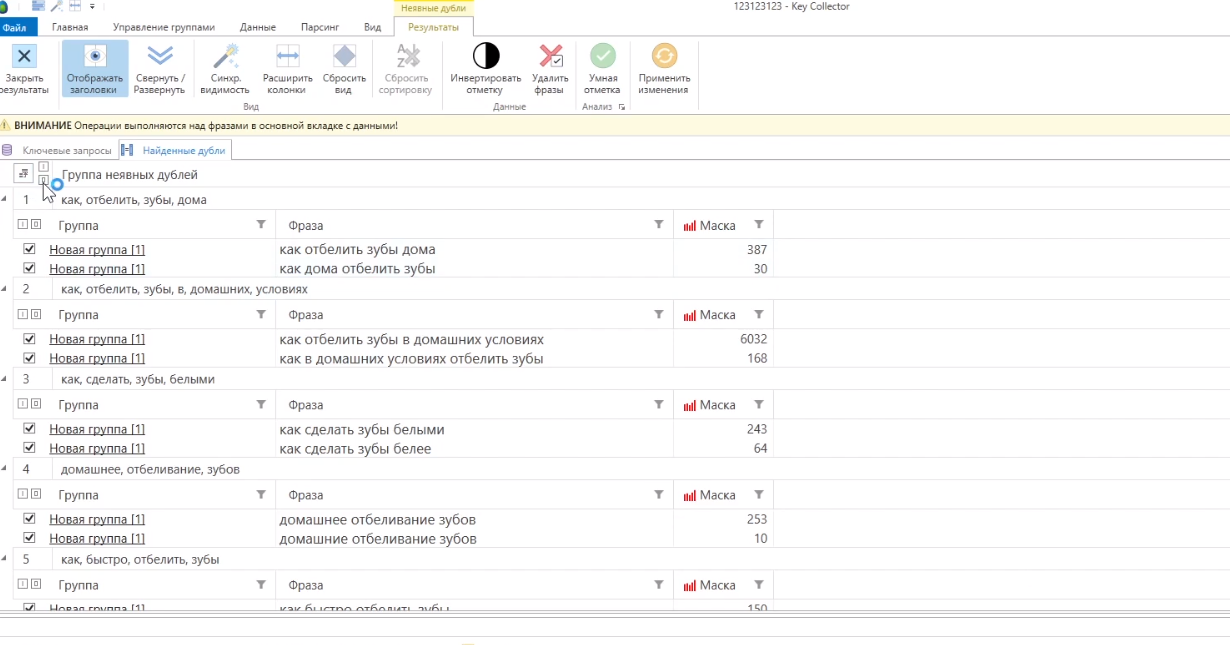
Например, в паре одинаковых запросов, отличающихся только порядком слов, «как отбелить зубы дома» и «как дома отбелить зубы» видно, что у первого (387) она выше, чем у второго (30). Таким образом, в данном случае второй запрос не нужен.
Снимаете выделение с фраз и нажимаете кнопку «Умная отметка». И сервис отметит те запросы, у которых частота ниже. В принципе, уже на этом этапе можно нажать «Удалить фразы», затем «Применить изменения» — и сервис их удалит из основной таблицы.
Но рекомендуется не делать так, а после нажатия «Умной отметки» пройтись по списку и посмотреть, а нет ли пар запросов, у которых значения частоты довольно близки. Допустим, частоты 50 и 24, где отличаются не на порядок, как, например, выше, где 33 и 5. Запросы с частотой 5 лучше удалять. А вот в таких случаях, как первый пример (где 50 и 24), стоит оба взять в работу, потому как они, в принципе, оба значимы. То, что они отличаются только порядком слов абсолютно не означает, что они могут быть на схожих позициях. Вполне возможно, что один может быть на первом месте, а второй на 20. Потому в данном случае рекомендуется отслеживать оба, потому снять выделение со второго запроса.
Ну и после подобной проверки уже можно нажать «Удалить фразы», затем «Применить изменения». И в результате в основной таблице станет меньше запросов, уже без дублей, которые отличаются друг от друга только словоформами и прочим.
Что касается синонимов, то с ними можно возиться и вбить список в настройки программы, но, как правило, результат получается некорректным, потому что выдача по синонимам может отличаться (и обычно отличается) очень сильно. Потому такие запросы всё же не стоит считать очень похожими. И если уж по словоформам отличается, то с синонимами, если запрос имеет частоту, точно нужно брать оба варианта.