Уфа
Как работать с семантикой при продвижении на западном рынке

Автор статьи
Андрей Буйлов
В данной статье мы рассмотрим, как работать с семантикой, со списком вопросов под западный рынок. Какой нужен минимальный необходимый набор инструментов для сбора семантики, которым можно пользоваться. Каким бесплатными инструментами можно собирать семантику и кластеризовать её.
Самый базовый инструмент из платных — Ahrefs. С помощью него можно закрыть в принципе до 80% потребностей по поисковым запросам в англоязычном сегменте, и кроме этого можно на ютубе собирать и т.д. Ещё есть SEMrush или Serpstat — любой из этих трех ведущих аналитических сервисов можно использовать и с любым покрывать основные потребности в работе с ключевыми словами: анализировать конкурентов, подбирать семантику и так далее.

Что касается кластеризации, то тут можно порекомендовать российский сервис — Rush Analytics. У них хорошие способы кластеризации, можно изучить материалы — софт, хард и так далее.
Что касается сбора семантику: Google Keyword Planner можно использовать, но при этом следует учитывать, что это инструмент не выдаст вам многих запросов, которые хотите увидеть. То есть он намеренно скрывает часть поисковых запросов. Будете ли просто собирать по ключу или анализировать сайты или страницы конкурентов, много запросов вы не увидите. Поэтому обязательно нужно дополнять.
Сейчас очень хороший и популярный тренд в англоязычном сегменте — сбор вопросительных запросов. То есть люди часто в поисковых запросах подразумевают вопрос. Например «выбор сноуборда» подразумевает вопрос «какой сноуборд выбрать». И вот если такие запросы получите и будете органично вписывать в текст на ваших страницах, то это увеличит и релевантность, и то, что ваши страницы на интент пользователя будут более полно отвечать.
Один из вариантов — на все страницы (особенно внутренние) добавлять блок вопросов и ответов в конце. Перед комментариями, к примеру, на страницах товаров, с услугами или информационных. Если обязательно добавить такой блок, то это хорошо работает для Google. Можно разделить FAQ разметкой и вы получите такую «гармошку» под описанием вашего сайта из вопросов. Вы наверняка встречали, есть такие блоки People Also Ask, например.
Существуют парсеры этих вопросительных подсказок, и Google выводит FAQ микроразметку. Особо продвинутые сеошники в эту разметку в выдаче размещают еще и эмодзи. Получается еще более кликабельно, потому что каждая строчка этой «гармошки» содержит в себе иконку и дополнительно привлекает внимание.
Обзор инструментов
Бесплатный Answer the Public
Для сбора таких вопросительных запросов можно использовать answerthepublic.com. То есть «спросить публику».
Вводить запросы можно на русском, можно на английском — языки поддерживаются.
Если говорить о англоязычных, то в строке страны «Великобританию» лучше поменять на «United States» — чтобы больше результатов получить, потому как в Англии далеко не всегда весь спектр семантики присутствует.
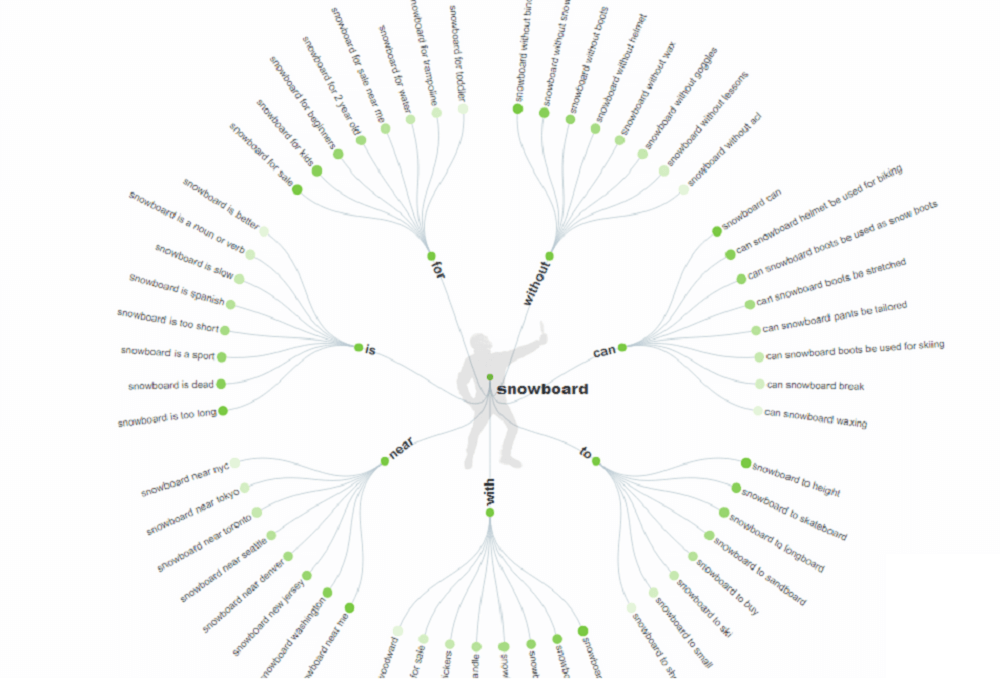
В результате подгружается и визуализация, и дата. Есть блоки «вопросы» , «сравнения», в «алфавитном порядке», «похожие запросы» и так далее. То есть обычная схема, многие знакомы с этим сервисом. Например, что-как-когда и так далее. Все эти запросы в виде вопросительных структур.

Можно сохранить в виде картинки, можно сохранить в виде CSV. А также посомтреть другие вариант, например сравнения.
Ahrefs. Инструмент Keyword Explorer
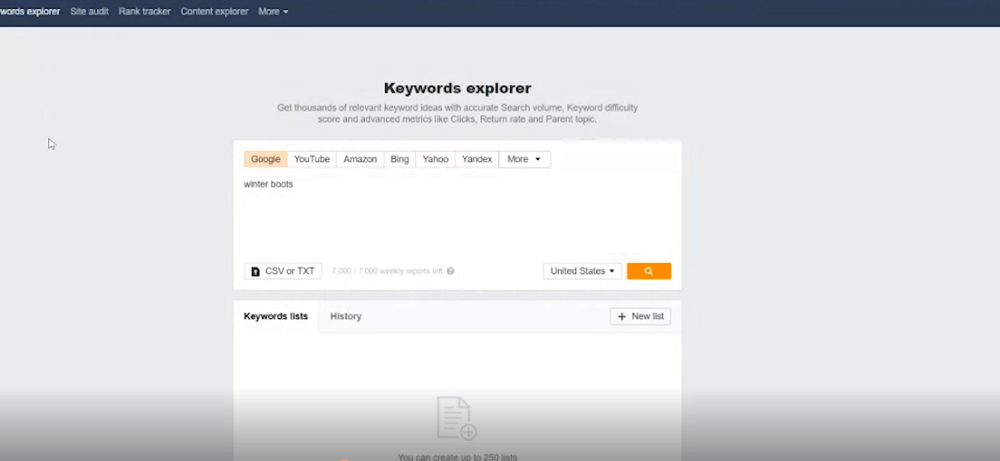
Какие могут быть варианты сбора семантики?
Например, набирается в окошке «winter boots». Дается потенциал трафика — 23 тысячи в месяц и примерная конкуренция — 14, то есть средняя. Рекомендуется использовать до 20-30 — по ним проще прдудинуться. И не стоит обращать внимание на запросы с конкуренцией 60-80 — очень долго и очень дорого получится. намного проще будет продвигаться по более простым запросам.
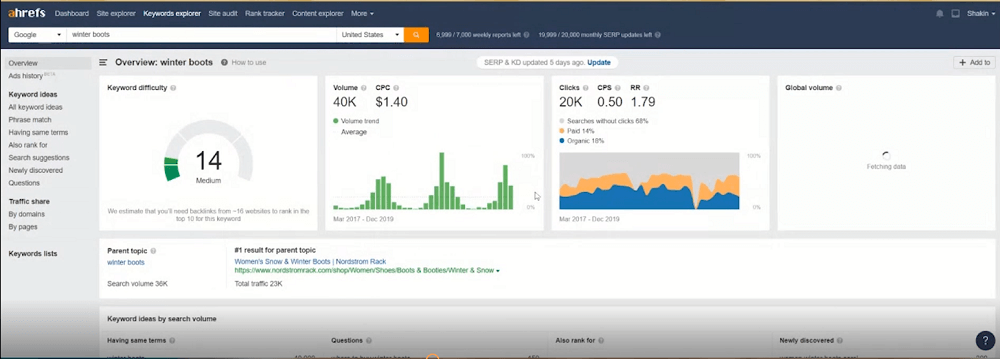
Здесь же инструмент выдает анализ ТОПа со всеми характеристиками, можно увидеть новичков, которые только-только туда попали. Есть еще один интересный момент — вопросы. Блок отдельно вопросов.

В этот блог также можно попасть через меню слева, вкладки Keyword ideas
или Questions.
Здесь в конце можно как раз увидеть список запросов. Можно их отсортировать по конкуренции (лучше использовать до 20-30, как уже было сказано). Можно использовать различные фильтры: по фильтрам, по частотности и другие. Возможно выбрать запросы, которые наиболее подходят именно вам. Например, возьмем слово «warm», введем его.
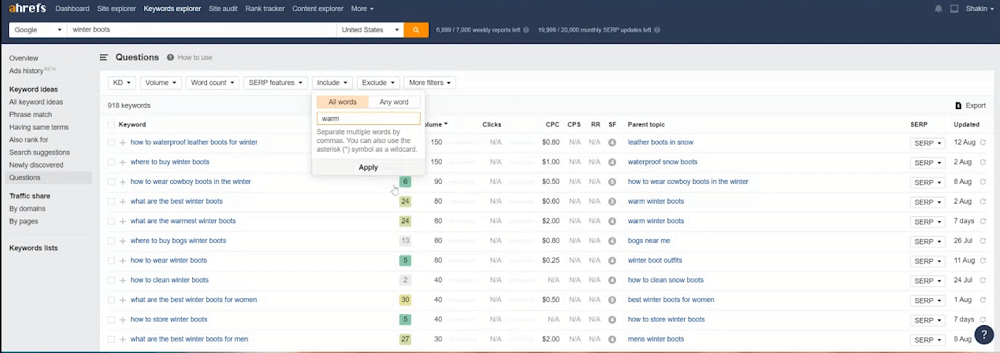
И сервис подгрузит данные с этим словам, и среди этих запросов можно уже выбрать те, с которыми можно работать.
Бесплатный сервис — Ubersuggest
Еще один сервис, которые можно порекомендовать — Ubersuggest (neilpatel.com/ubersuggest). Это сервис Нила Потели, он его купил и сделал редирект на свой сайта.

Для примера введем «Board games».
Если вы залогиньтесь в этом сервисе через Google, то будете получать больше данных. Но на данный момент в англоязычном сегменте Ubersuggest является самым функциональным сервисом, который дает больше всего данных по ссылкам, по ключевым словам и по топовым страницам, чем все остальные вместе взятые бесплатные. Он сейчас даёт как можно больше бесплатных данных.
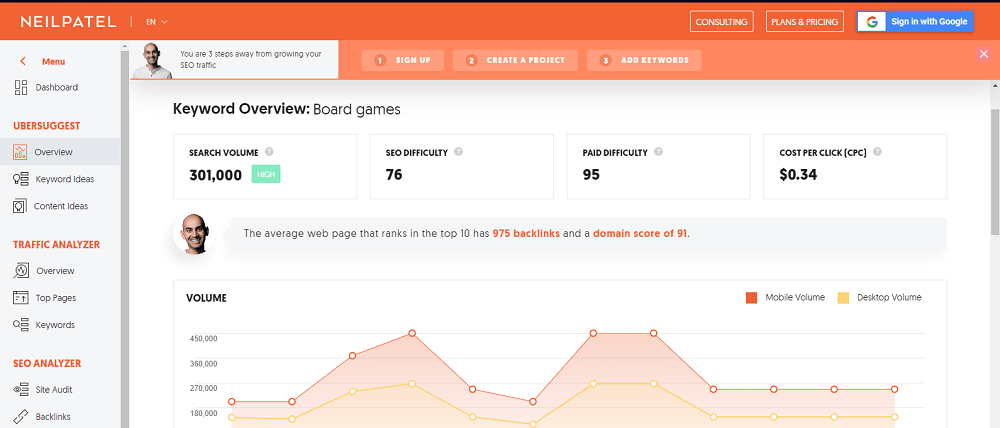
Если бюджет ограничен можно и нужно работать именно с Ubersuggest. Здесь есть общие данные, можно посмотреть все ключевые слова. Можно посомтреть конкуренцию, сео и так далее. То есть вполне функциональный сервис, здесь также как и на Answer the Public есть вопросительные запросы. Можно посомтреть не только идеи по ключевым словам, но и идеи по контенту. То есть прямо брать и использовать топовые страницы конкурентов как ориентир для своих материалов.
ScrapeBox
Еще один вариант для сбора семантики — платная программа scrapebox.com. У нее разовая плата? и своих денег она стоит однозначно.

У нее большой плюс в том, как она собирает семантику. Вы загружаете свои запросы, затем вводите различные признаки сайтов (на PHP они, на Drupal и т.д.) и можете собирать. Но самое интересное — здесь будет кнопки Scrape и Keyword. Когда вы введет запрос, например, сноуборд, программа соберет запросы с этим словом из большого количества различных источников: с амазона, с ютуба и так далее. И после того, как их соберет, на основе каждого запроса сделает новый поиск.
Например, собрала полторы тысячи по сноуборду. Если указали сделать 4 итерации, то она эти полторы тысячи собранных запросов перекидывает в изначальное поле поиска, каждый запрос также пробивает — и вы уже собрали 5 тысяч. Затем она эти 5 тысяч вновь перекидывает в основное поле и по ним ищет. И таким образом делает те самые 4 разы. Иными словами, вы сможете собрать огромное количество запросов. И если прокси у вас быстрые, то много времени это не займет, и получите очень много запросов, с которыми дальше можно работать: чистить, кластеризовать и так далее.
И как уже говорилось, в плане кластеризации можно использовать Rush Analytics.
Связки Ahrefs, Ubersuggest и Answer the Public достаточно, чтобы собрать 99% нужной вам семантики. И еще как вариант использовать ScrapeBox.
Тот же Ahrefs можно не покупать каждый месяц, достаточно заплатить за один, собрать все необходимые данные в этот период по всем тематикам, по всем конкурентам — и обеспечите себя объемом работ на несколько месяцев.