Уфа
Как собрать поисковые подсказки в Яндексе и Google

Автор статьи
Андрей Буйлов
Что такое поисковые подсказки
Поисковые подсказки – это подсказки от Яндекса и Google, которые выходят в ответ на начало запроса пользователя. Т.е. к примеру вы набираете в поисковой строке слово «купить», и Яндекс уже предлагает, что бы мы хотели купить. Нам нужны «купить пластиковые окна», в данном случае один из вариантов нам подходит, мы кликаем по предложенному варианту.
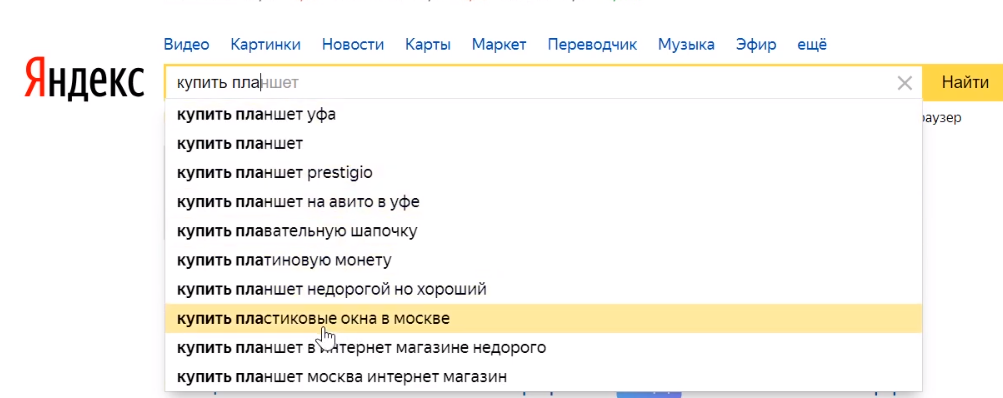
В эти подсказки часто попадают запросы, которые, не отображаются в сервисах по сбору ключей, например в Яндекс.Wordstat и в других подобных. Поэтому мы эти подсказки используем практически обязательно во всех продвижениях — там можно найти много нужных запросов.
Какие бесплатные сервисы есть для сбора подсказок?
Для сбора подсказок есть платные сервисы, и инструменты для их парсинг есть в большинстве платных сервисов работы с семантикой. Однако как же собрать подсказки бесплатно?
Для бесплатного парсинга есть две программы от Александра Люстика: Словодер и СловоЕБ. Можно зайти на сайт Seom.info (http://seom.info/tools/) и скачать их. Александр Люстик также является создателем программы Key Collector, но она платная, поэтому в данной статье мы ее рассматривать не будем.
Словодер
Словодер — это довольно устаревшая программа и уже не решает тех задач, которые нам нужны. Тем не менее, рассмотрим как с ней работать.
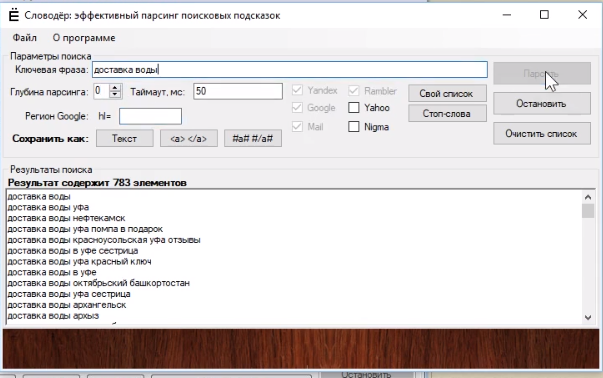
Для примера возьмем запрос «доставка воды». Вводим его в поле «Ключевая фраза», выбираем значение параметра «глубина парсинга», регион, поисковики, которые будет парсить — и нажимаем кнопку «Парсить».
Это программа парсит быстро и много. Сервис собрал 700 элементов и остановился – непонятно, он собрал все или только часть. В «настройках» программы можно добавить прокси-сервер, но только один. Это не очень здорово.
После того, как спарсил подсказки, сохраняем это как текст (в соответствующем окне), и дальше с этим можно работать.
Словодер для работы не рекомендуется, но как вариант бесплатного сервиса – можно рассматривать.
СловоЕБ
Чуть лучше вторая программа, у которой довольно экстравагантное название — СловоЕБ. Это урезанная версия Key Collector, но она бесплатная.
Какие выбрать настройки?
Зайдем в «Настройки/Парсинг», вкладка «Подсказки» и рассмотрим, какие параметры можно установить.
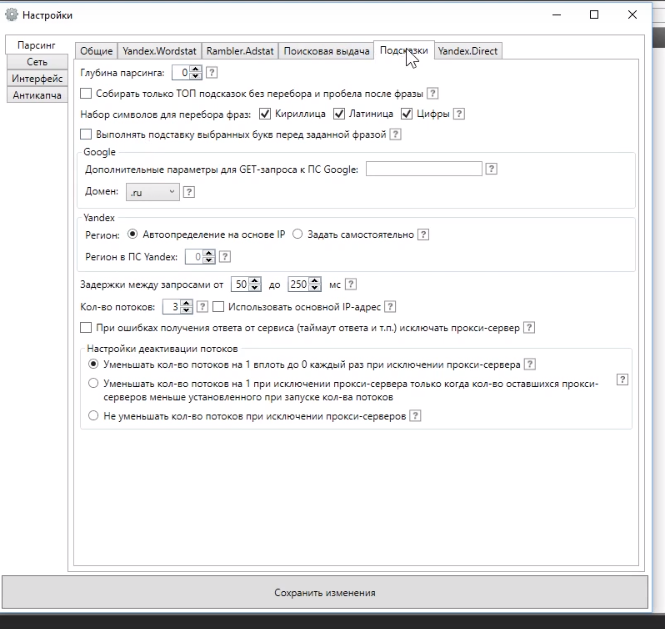
● Глубина парсинга. Лучше всегда выставлять здесь 0. Исключение – если у нас мало подсказок. В справке (знак вопроса рядом  ) можно узнать об этой опции подробнее, но в большинстве случаев она не понадобится.
) можно узнать об этой опции подробнее, но в большинстве случаев она не понадобится.
● Пункт «Собрать только топ подсказок без перебора и пробелов после фразы». Что здесь имеется в виду?
Когда мы в поисковой строке Яндекса вбивали свой запрос — «пластиковые окна» — нам выдавались подсказки «пластиковые окна в москве», «пластиковые окна купить» и т.д. Но можно набрать основной запрос, поставить пробел и начать набирать следующее слово — и поисковик предложит нам варианты продолжения запроса. Например, если набрать «пластиковые окна й...» — будет одни варианты подсказок; «пластиковые окна 1...» — другие.
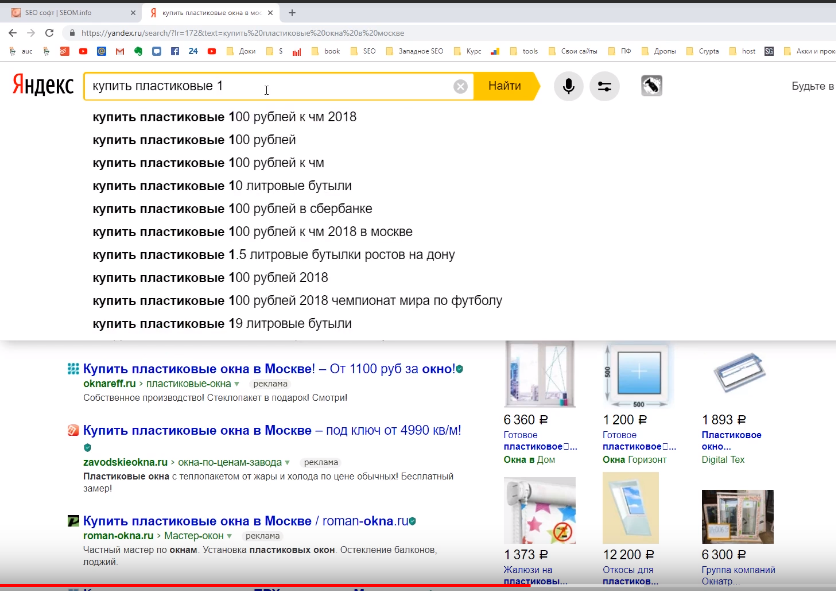
И так наша программа перебирает все эти варианты. Однако, если ставим галочку в пункте «без перебора», то подобные подсказки учитываться не будут. Список будет более чистый, но и более короткий. Если же галочку не поставить, подсказок будет намного больше, и это здорово.
● «Набор символа для перебора фраз». Выбираем символы, которые будем подставлять: кириллические (русские), латиница (английские) и цифры. В данном случае выбираем все три опции.
● «Выполнять подставку выбранных букв перед заданной фразой». Буквы будут подставляться до ключевой фразы, а не в конце. Это будут другие фразы, не выбираем эту опцию.
● Параметры нам не понадобятся.
● Домен. Если русскоязычный сегмент выбираем, то выбираем как правило – ru, .
● Регион. В данном случае стоит «автоопределение на основе IP». Прокси у нас отключены, мы парсим оттуда, откуда заходим. Соответственно запросов для города, где находимся, будет несколько больше, чем других. Это не очень здорово, поэтому при реальном парсинге лучше во вкладке «Регион» выбрать «Задать самостоятельно» и соответственно задать город. Скажем, Москва (код 213). Коды городов можно посмотреть на самом Яндексе.
● Вкладка «Задержки между запросами» – стандартных 50*250 миллисекунд вполне хватает.
● Количество потоков: если у вас нет проксей, то лучше делать 1 и придется использовать свой IP адрес. Если мы работаем без проксей (а в большинстве случаев это именно так), парсится абсолютно нормально, не блокирует.
Сохраняем изменения.
Работа в программе
Нажимаем кнопку «пакетный сбор поисковых подсказок», в появившееся окно вбиваем наши запросы.
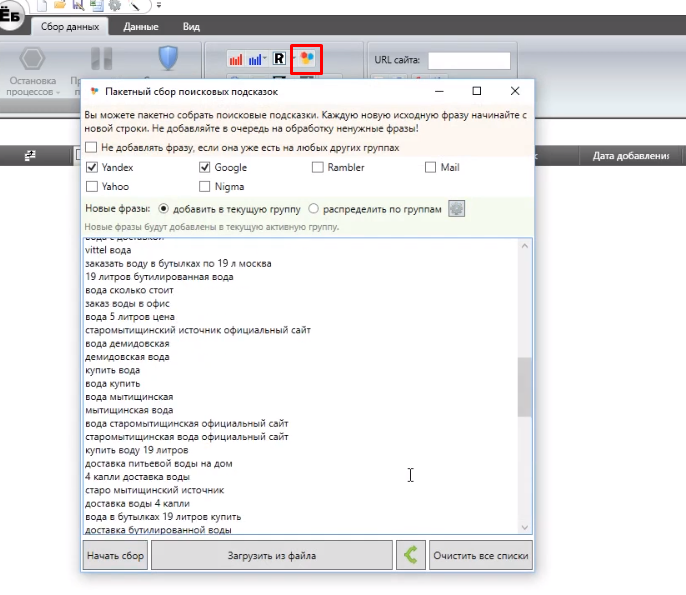
В этом же окне выбираем поисковики, которые мы хотим парсить, допустим Яндекс и Google. И жмем «Начать сбор».
Вот таким образом сервис будет собирать запросы. И дальше, так как их будут десятки тысяч, то нам нужно будет отдельно пробивать их частоты. Это отдельная история, лучше это делать в специализированных сервисах, например в Муравейник tools либо в платной версии Key Collector. Но не через вкладку «лупа».
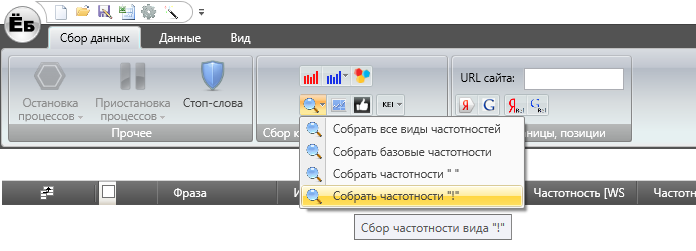
Это сбор частот через Яндекс.Wordstat. Почему не через него? Он будет собирать данные по одному запросу.
Мы это делаем через Key Collector, где у нас вбиты:
1. аккаунты Яндекс, через которые он логинится,
2. обязательно прокси, так как это большой объем парсинга.
Через инструмент «Прогнозы Яндекс Директ» мы закидываем туда запросы пачками и пачками забираем данные. По времени парсинг 10 000 слов занимает несколько минут, а поштучный через Wordstat — часы. К тому же рано или поздно Яндекс забанит IP и заблокирует аккаунты на время или навсегда, т.к. это очень большой объем парсинга.
Иногда можно парсить в Яндекс Wordstat, но делать это огромным количеством серверов и аккаунтов.