Уфа
Уфа
Москва
Россия
Адрес в Уфе:
ул. Зорге 11/1 корп.2, офис 408
пн–пт 8:45 – 17:45
обед 13:00 – 14:00
Адрес в Москве:
ул. Большие Каменщики, д. 1, офис 304
пн–пт 6:45 – 16:45
обед 13:00 – 14:00
- Главная
- Блог
- Видеоуроки по SEO
- XML лимиты: где и как использовать?
XML лимиты: где и как использовать?

Автор статьи
Андрей Буйлов
XML лимиты, которые покупаются у сервисов XMLProxy для Яндекса, XMLRiver для Google, в основном используются для парсинга поисковой выдачи. Какие программы это могут делать? Например, Key Collector, KeyAssort — то есть все сервисы и программы, которые парсят поисковую выдачу для последующего анализа.
Как использовать: пошаговая инструкция
Рассмотрим, как это делать на примере сервиса Key Collector.
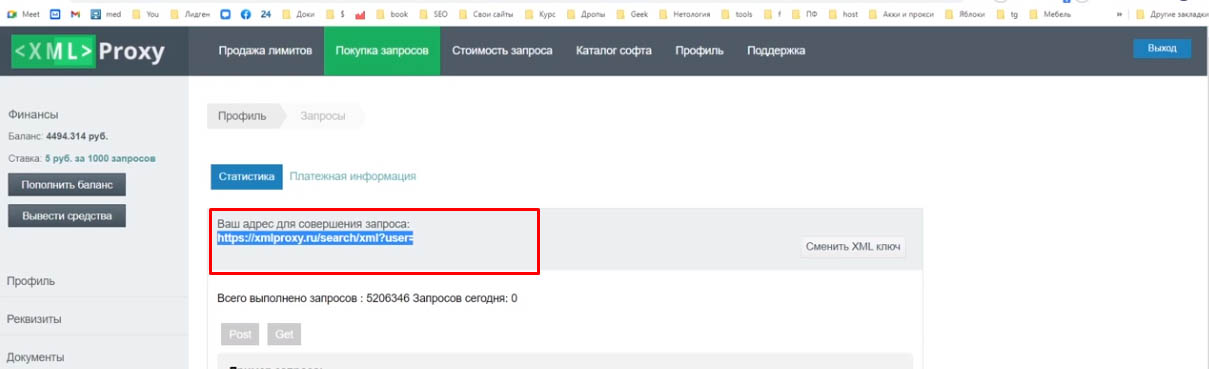
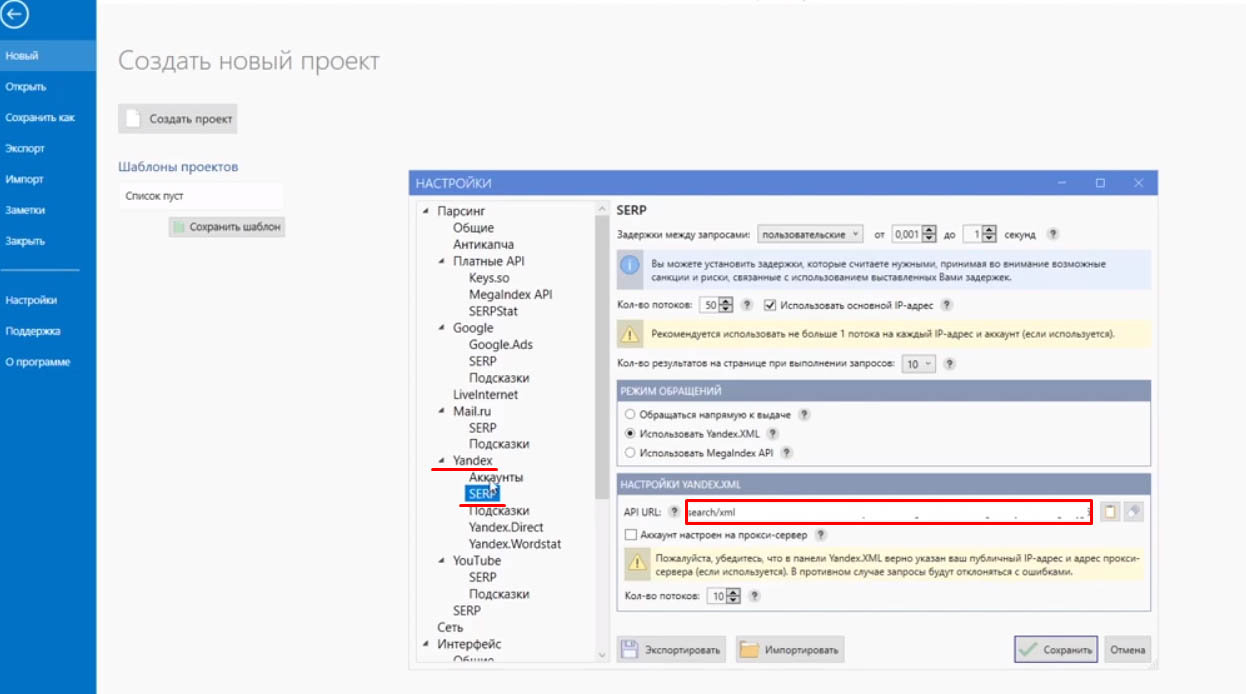
У XMLRiver делаете аналогично: находите там же Google — SERP, выбираете «Использовать XMLRiver» и вбиваете ключ.
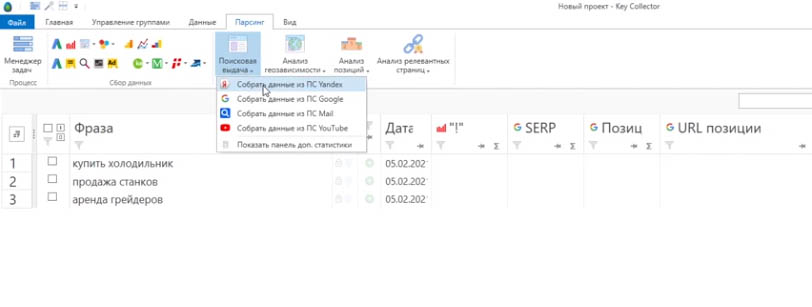
После того, как вставили ключ там, где вам нужно, жмете сохранить. Открывается окно с новым проектом. Далее заходите во вкладку «Добавить фразы» и в появившемся окне вбиваете нужные запросы.
Вам нужно, например, собрать поисковую выдачу по ним:
Собирается всё довольно быстро. Тут можно посмотреть анализ SERP: общее количество найденных документов, количество вхождений в топы (в примере в настройках было указано, чтобы они собирались по неточным вхождениям), количество главных страниц в топе.
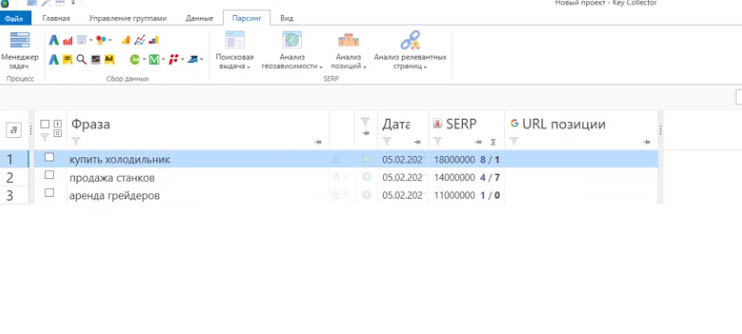
Если зайти во вкладку «Данные SERP» (внизу страницы), то можно посмотреть, что там конкретно было. Можно увидеть, что там выгружен топ-30. Это все сделано через XML, взятый у XMLProxy.
Вот пример того, как это можно использовать.