Уфа
Можно ли без прокси собирать поисковую выдачу в KeyCollector и KeyAssort?

Автор статьи
Андрей Буйлов
В статье рассмотрим вопрос, можно ли при сборе поисковой выдачи в программе Key Collector и KeyAssort работать без прокси-серверов. Подписчик спрашивает: «А можно ли работать без прокси как в Key Collector? Или обязательно только с прокси?»
Вопрос был задан к видео про KeyAssort, потому сейчас и Key Collector посмотрим, и KeyAssort тоже.
Key Collector
Заходим в настройки Кей Коллектора: «Файл» — «Настройки». Нажимаем на кнопку SERP во вкладке Google.
И видно, что у меня выставлено «Использовать XMLRiver», собственно, через него мы обычно и парсим. То есть API строку я взял оттуда.
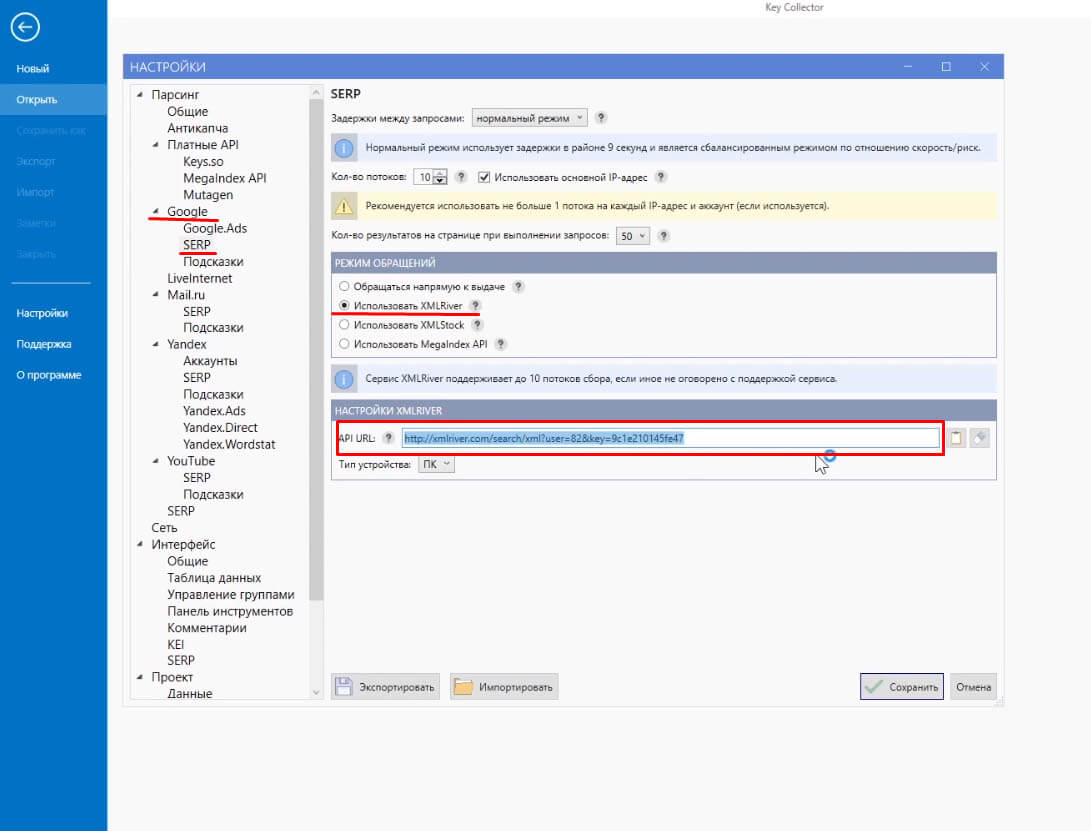
И я работаю без прокси серверов, здесь они мне не нужны. И количество потоков стоит 10.
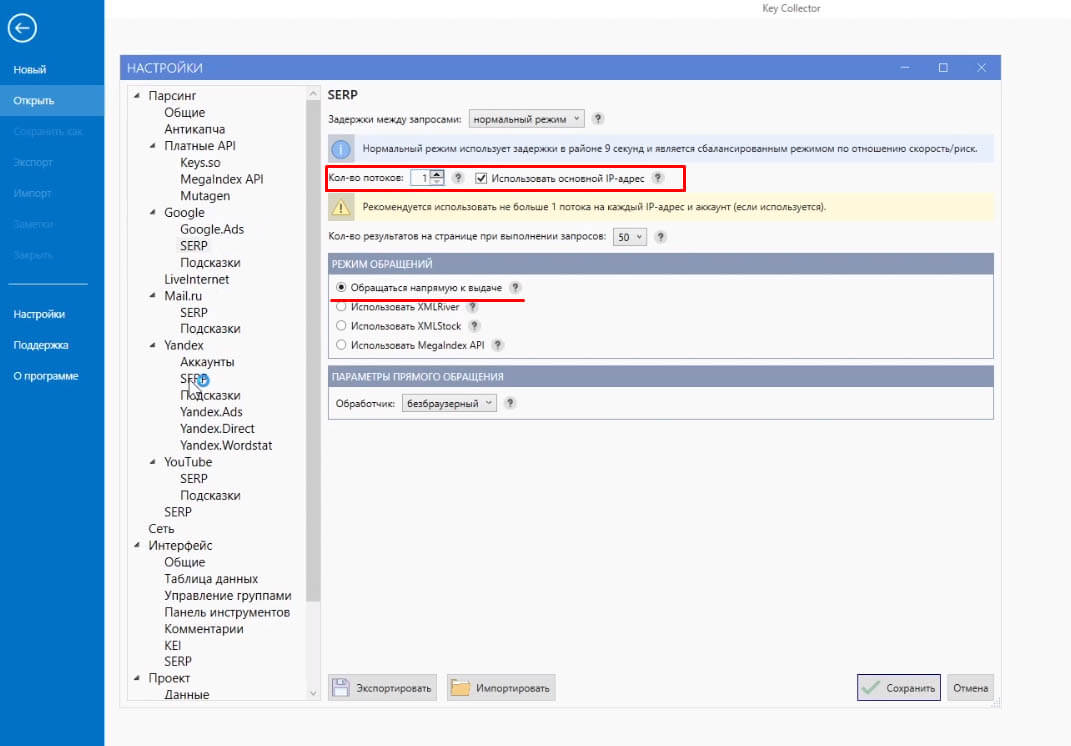
Если же я захочу парсить напрямую — допустим, жадничаю и надеюсь, что Google меня не очень будет блокировать — тогда выбираю пункт «Обращаться напрямую к выдаче». В пункте «Параметры прямого обращения» можно выбрать безбраузерный и браузерный режим. И — самое главное — если нет прокси-сервера, количество потоков должно быть равно 1. Потому что в случае, когда мы парсим через сервис (XMLRiver Google, через XMLProxy Яндекс), то ограничены только рамками внутри сервиса. Я обычно ставлю 10 потоков, если выбрать больше, периодически сервисы начинают падать, глючить и так далее. Поэтому ставлю всегда 10 и галочки напротив «Использовать основной IP-адрес».
Если же мы парсим напрямую, то поток всегда должен быть 1, потому что для поисковой системы всегда подозрительно, когда с одного IP-адреса несколько действий совершаются.
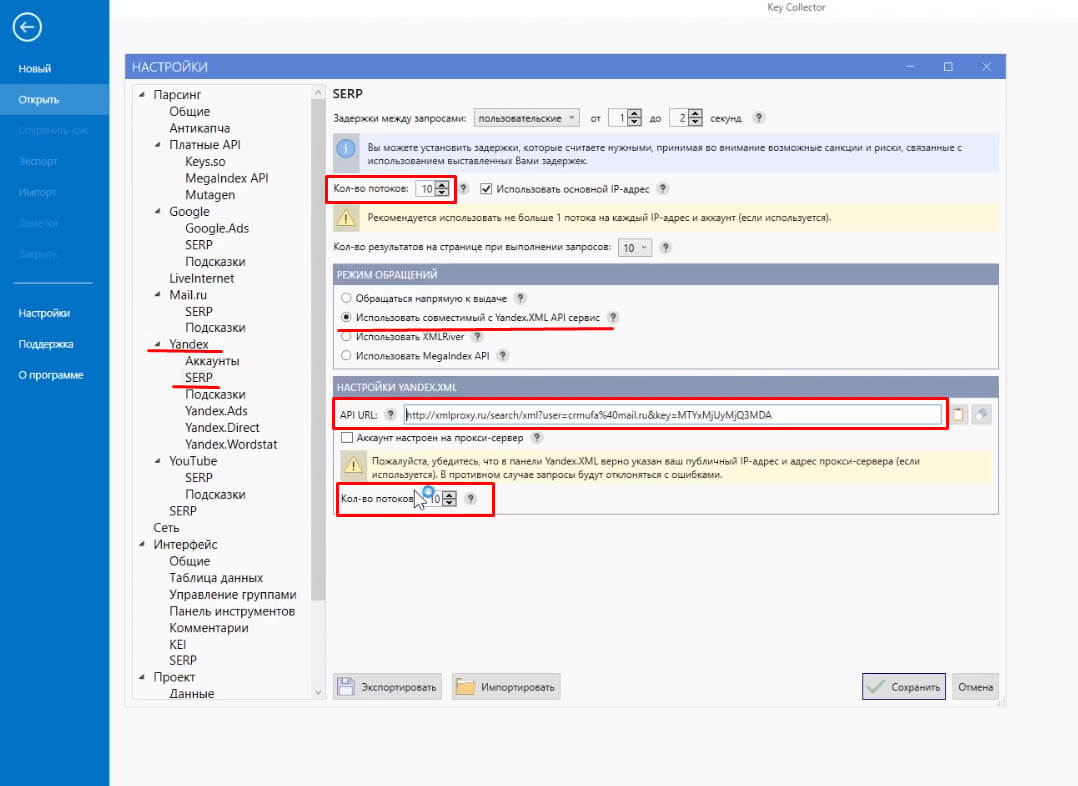
В Яндексе то же самое. Нажимаем на SERP во вкладке Yandex. Сейчас у меня через Яндекс XML. Но не сам Yandex XML, потому что он очень неудобен при парсинге, у него есть кроме суточных лимитов еще и почасовые лимиты. У нас много продвигаемых проектов, потому лимитов на балансе Яндекса много. То есть нам бы их точно хватало для парсинга, но там есть еще и почасовые лимиты, а работаем мы в основном в дневное время, а днем как раз эти лимиты очень скромные. И поэтому через Yandex XML работать стабильно неудобно, мы используем XMLProxy.
Таким образом, в пункте «Режим обращений» выбираем «Использовать совместимый с Yandex XML API сервис», в «Настройках Yandex XML» вставляем API УРЛ, и количество потоков выбираем 10.
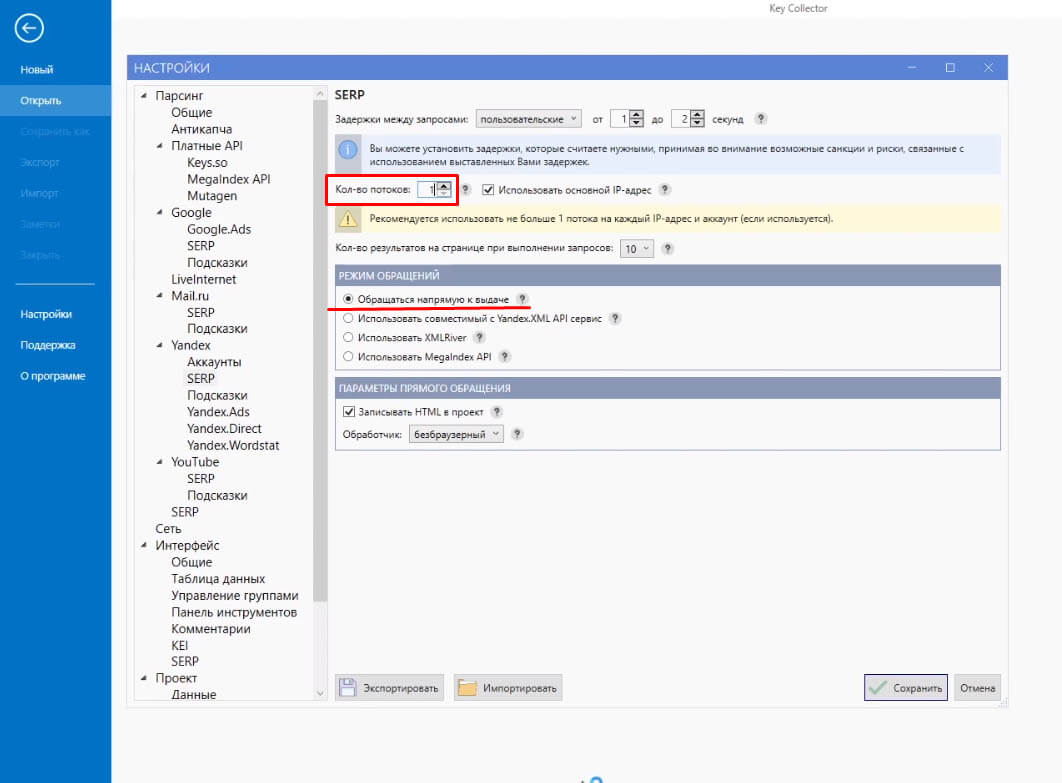
Когда хотим обращаться напрямую, то же самое, что и с Google: количество потоков надо уменьшить до 1, если парсим напрямую и нет прокси-серверов.
KeyAssort
По KeyAssort аналогичная абсолютно история. Заходим в «Сервис» — «Настройки программы». В появившимся окне выбираем вкладку «Сбор данных».
И тут есть:
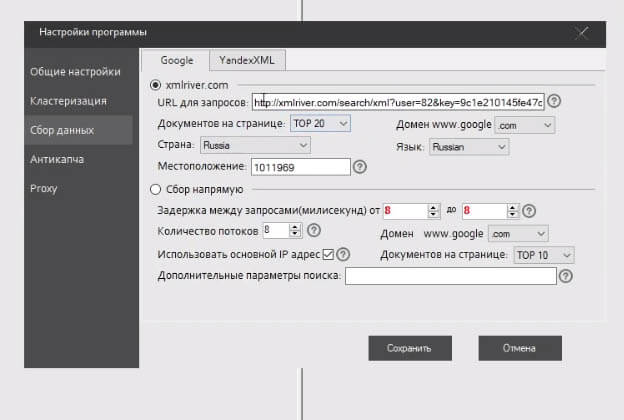
Здесь можно выбрать парсить напрямую («Сбор напрямую»). Количество потоков, конечно, должно быть 1. Галочки на «Использовать основной IP-адрес». И, опять же, если во вкладке «Proxy» прокси-сервера мы не добавляли, то обязательно надо собирать все в один поток.
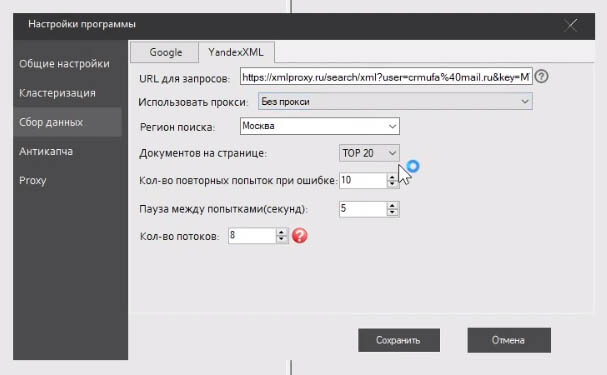
Тут, я так понимаю, у них нет сейчас такой возможности, делать напрямую, у них только парсинг через XML сейчас, соответственно прокси там вообще не нужен. И также абсолютно нормально может быть 8-10 потоков при парсинге с XMLProxy.
Мы давно уже при такой аналитике не парсим напрямую ни Google, ни Яндекс. Если Яндекс еще как-то есть смысл, то Google гораздо более требователен к разнообразию прокси-серверов и этого всего, и капчу начинает выдавать чаще, и в итоге становится очень неудобно работать.
Когда мы парсим для более глубокой аналитики — например, в нашем Муравейник Tools мы парсим выдачу напрямую из Яндекса и Google. Но для кластеризации, для простого анализа выдачи это не нужно, и можно парсить, используя XMLProxy для Яндекса и XMLRiver для Google. И по моему сейчас XMLRiver добавил и Яндекс тоже.
Таким образом, через Key Collector можно парсить напрямую, не используя сервисы, если у вас нет прокси, а через KeyAssort Google тоже можно напрямую, но я не рекомендую, а Яндекс нельзя.